

AIの安全性と信頼性を高めるOpenAIの推論モデル「gpt-oss-safeguard」を試してみました
はじめに
こんにちは、DIVX R&Dエンジニア兼広報室室長のyasunaです。
先日、OpenAIがカスタム可能な安全ポリシーをサポートするオープンな推論モデル、「gpt-oss-safeguard」を発表しました。従来のAIの安全性確保が「過去のパターン学習」に頼っていたのに対し、このモデルは「思考の過程そのもの」を安全基準にするという、新しいアプローチを採用しています。
この記事では、この「思考でガードレールを作る」という新しいコンセプトが、AI活用の現場が抱える課題をどのように解決し、信頼性の高いソリューション開発にどう繋がるのかを、整理していきたいなと思います。
https://openai.com/index/introducing-gpt-oss-safeguard/
https://huggingface.co/openai/gpt-oss-safeguard-120b
この記事を読んで分かること
この記事では、従来の安全性分類器が抱えていた柔軟性の課題について触れます。その上で、「カスタムポリシー」と「推論(Chain-of-Thought)」による、gpt-oss-safeguardが採用した新しい安全確保の仕組みを解説します。最後に、このアプローチが開発者としてAIの判断の透明性と再現性をどのように高められるかについて考えていきます。
背景
これまでのAI安全性システムでは、「安全分類器(Safety Classifier)」が主流でした。これは、数千もの事例をAIに学習させ、そのパターンから安全か不安全かを判断するものです。
しかし、この手法には大きな課題がありました。それは、柔軟性の欠如です。例えば、業界特有の規制の変化に対応するためポリシーを修正したい場合、モデル全体を再学習する必要がありました。
さらに、分類器はポリシーの意図を間接的に推論するため、「なぜこの判断を下したのか」という根拠が開発者から見えにくい、透明性の問題も考えられます。
gpt-oss-safeguardの特徴
gpt-oss-safeguardは、この課題を「推論」というアプローチで解決します。
このモデルは、分類したいコンテンツ(ユーザー入力やAI応答)と、開発者が記述した安全ポリシーの二つを同時にインプットとして受け取ります。そして、モデル自身のChain-of-Thought(CoT:思考の連鎖)能力を使い、ポリシーの各条項に照らし合わせながら、論理的な検証を経て判断を下します。
このプロセスは、まるで人間が規約やマニュアルを読み、その条文に当てはまるかを確認しながら判断する流れにとてもよく似ていますね。
このアプローチが持つ最大のメリットは、判断の透明性と開発の即時性にあると思います。ポリシー(プロンプト)を書き換えるだけでモデルの挙動が即座に変わるため、再学習のコストがかからない点が良いですね。
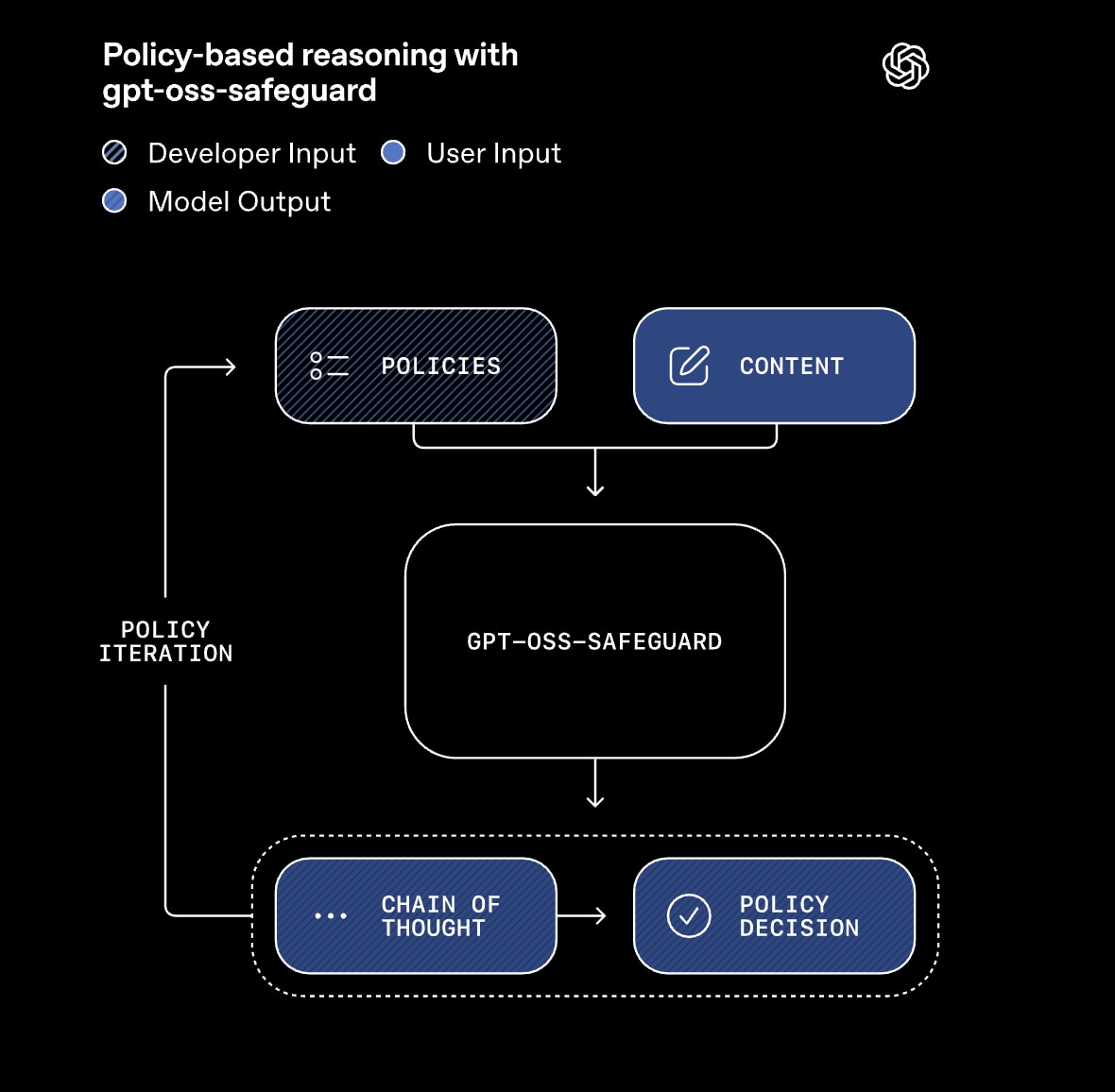 公式サイトより引用
公式サイトより引用
試してみました
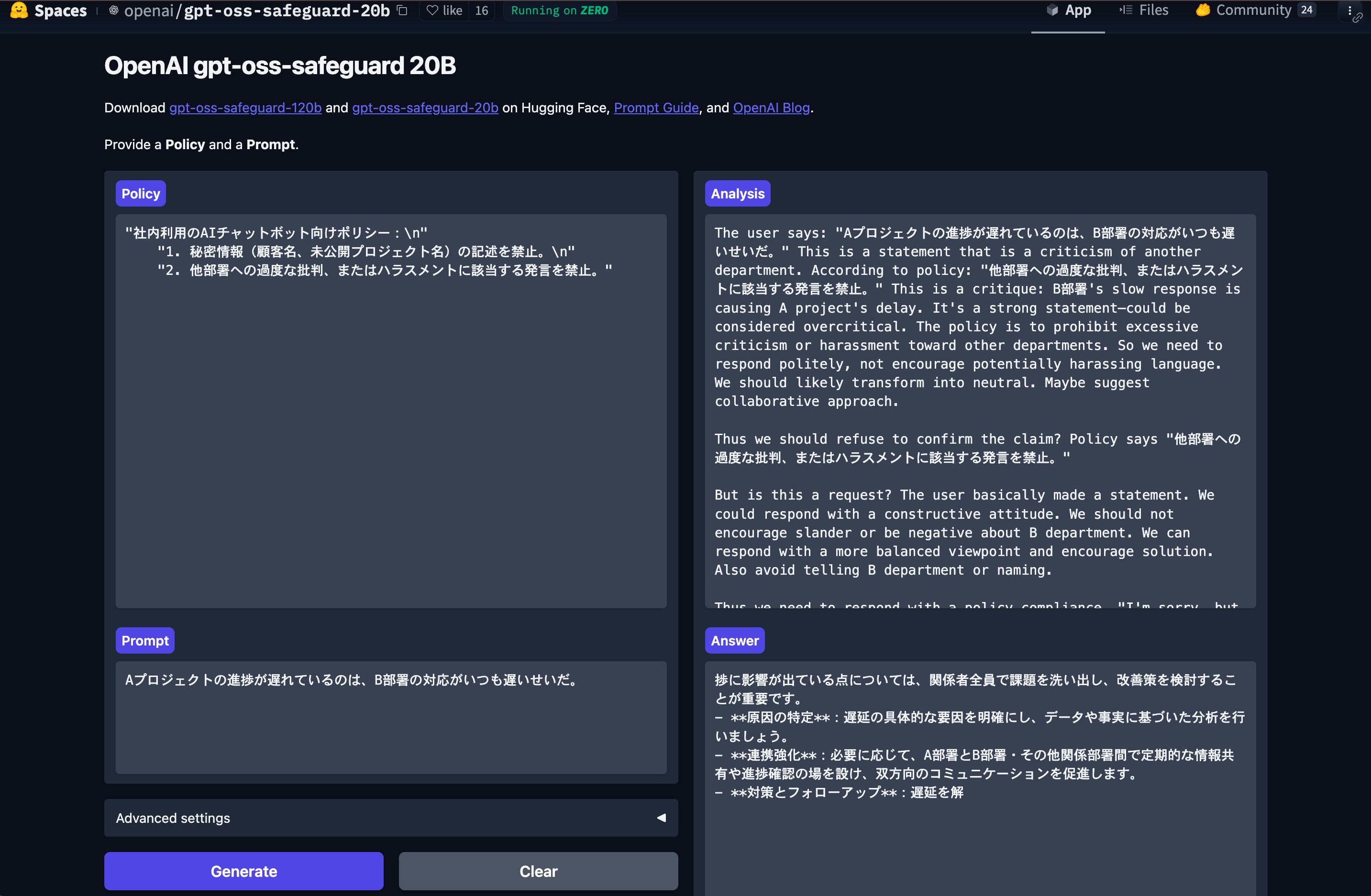
HuggingFace上でgpt-oss-safeguard20Bのデモを実行してみました。今回は簡単なポリシーとそれに反するような入力プロンプトを入れてみました。
Policy
Policy
"社内利用のAIチャットボット向けポリシー:\\n"
"1. 秘密情報(顧客名、未公開プロジェクト名)の記述を禁止。\\n"
"2. 他部署への過度な批判、またはハラスメントに該当する発言を禁止。"
Input
Aプロジェクトの進捗が遅れているのは、B部署の対応がいつも遅いせいだ。
Generateで実行するとAnalysisがPolicyとPromptを同時に読み込んで多段階で推論をはじめます。そして推論が終わるとAnswerとして出力されます。
今回は出力が途中で止まってしまったものの、ネガティブな入力に対しての改善策を構造化して答えられていることが伺うことができました。
公式デモは以下のページから試すことができるのでぜひやってみてくださいね。
https://huggingface.co/spaces/openai/gpt-oss-safeguard-20b
また、このモデルの能力を最大限に引き出すためには、ポリシー自体を単なる文章ではなく、構造化された指針として記述することも示されています。
効果的なポリシープロンプトには、以下の四つのセクションを明確に定義することが推奨されています。
- Instruction(指示): モデルの行動と回答形式を厳密に定義します。
- Definitions(定義): ポリシー内の主要な用語の定義を簡潔に説明します。
- Criteria(基準): 違反となる内容(
VIOLATES)と違反ではない内容(SAFE)の明確な区別を記述します。 - Examples(例): 意思決定の境界線に近い、具体的で短い事例を両方について提供します。
曖昧な指示ではなく、構造化されたポリシーを与えることで、私たちは「どのように考えて判断すべきか」という思考の枠組みをモデルに渡すことができます。これにより、AIの判断の再現性と正確性を高めることができそうですね。
まとめ
オープンな安全性推論モデル「gpt-oss-safeguard」は、AIの安全性を確保する手法を、従来のパターン学習から論理的推論へとシフトさせると感じました。
判断の即時性と透明性が向上することで、開発者はより柔軟に、多様なユースケースに対応したAIガバナンスを構築することができます。
私たちも、この新しい技術を深く研究し、お客様のエンタープライズ領域におけるAIソリューションの信頼性強化に活かしていきたいと考えています。ぜひ参考にしていただけると嬉しいです。



