

Document AIカスタムプロセッサで実現する構造化データ抽出の実践記
はじめに
エンジニアの皆さん、こんにちは。divxのエンジニアの鶴です。
私はTypeScriptやGoを主に使用してバックエンド開発に携わっており、特にドキュメント処理やデータ抽出のシステム開発を担当しています。これまでに、PDFや画像から情報を抽出するシステムを複数構築してきましたが、従来のOCRと正規表現を組み合わせたアプローチの限界を常に感じていました。
最近、新規プロジェクトでドキュメント処理のタスクにアサインされ、Google CloudのDocument AI、特にカスタムプロセッサの構築に取り組む機会を得ました。本記事では、その実践的な経験を共有し、同じような課題に直面しているエンジニアの方々の参考になればと思います。
この記事を読むことで得られること
Document AIの基本的な仕組みと、従来のOCRとの違いを理解できます
カスタムプロセッサの構築プロセス(アノテーションから学習、評価まで)を実践的に学べます
非構造化データの処理を効率化する具体的なアプローチを習得できます
従来のアプローチの課題
私の仕事でTypeScriptやGoでロジックを組む傍ら、常に厄介なのが、紙やPDFといった非構造化データの取り扱いです。
従来のシステムでは、PDFを画像として読み込み、OCRでテキスト化し、そのテキストに対してゴリゴリと複雑な正規表現を書いて、
「ここが金額だ」「ここが日付だ」と判定していました。これがまあ、レイアウトが変わるたびに改修が必要で、非常にしんどい作業です。
もしくは最近だと出力された文字列をLLMにプロンプトと一緒に投げることで任意の値を取り出すこともしました。
しかしこれですとなかなか精度を上げることに苦労します。
この問題を解決するために触り始めたのが、Google CloudのDocument AIです。
1. Document AIの仕組み:従来のOCRとの決定的な違い
Document AIが優れているのは、単に文字を認識するだけでなく、意味や構造を理解しているかのように処理をしてくれるところです。
単なるテキストではない「構造化された出力」
例えば、以下の画像のような請求書があったとします。従f来のOCRは「〇〇株式会社... 請求額 1,200,000円...」という長い文字列を返すだけでした。
Document AIは、あらかじめ学習されたモデル(プロセッサ)のおかげで、最初から「構造化されたデータ」として情報を返してくれます。
このデータ構造は、JSONで返却されているので後続のアプリケーション開発が非常に楽になります。
1.1 宣言的なアプローチを可能にする「プロセッサ」
Document AIはタスクに応じてプロセッサを選択するだけで済みます。複雑な機械学習モデルのチューニングは不要です。
しかしながら基本的な機能ですと特殊なフォーマットなどに対応できずに精度が落ちてしまいます。
そこで事前構築されたプロセッサを使うのではなく、今回は特定の企業独自のフォーマットを扱いたいがためにカスタムプロセッサを作成しました。
カスタムプロセッサはユーザーがそれぞれの独自のフォーマットを持った書類を学習させ専用の読み取りを作成することができます。
2. カスタムプロセッサの仕組み:学習と定義
カスタムプロセッサは、開発者が用意したアノテーション(ラベル付け)付きの訓練データを基に、AIモデルをゼロから、あるいは既存のプロセッサをベースに学習させる機能です。
以下のようにアノテーションを準備します。左枠名前の黒塗りのところに任意のアノテーションを作成します。
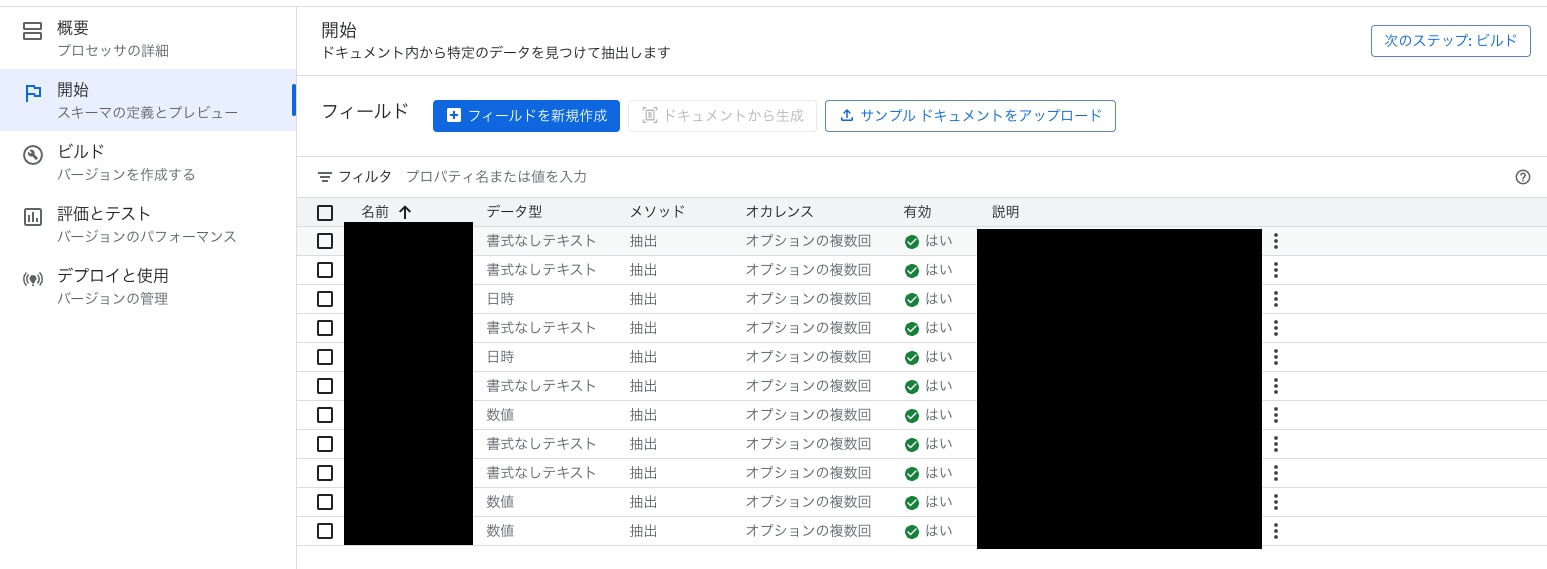
2.1. トレーニングデータの準備とアノテーション
カスタムプロセッサ構築の最大の作業は、このアノテーション(ラベル付け)です。
ドキュメントのアップロード:独自のPDFや画像をDocument AI Workbenchにアップロードします。
フィールドの定義:抽出したいデータの項目(例: CustomOrderID 、 SpecialTerm など)を定義します。
ラベル付け(アノテーション):アップロードしたドキュメント上で、定義したフィールドに対応するテキストをマウスで囲んでラベル付けします。
この作業を数十〜数百のドキュメントに対して行い、モデルを学習させます。僕が感じたのは、 学習データは多いに越したことはない、ということ。精度を上げるための地道な作業ですが、一度モデルが完成すれば、その後のメンテナンス負荷は激減します。
また、利用するお客様が増えればその分取り扱うドキュメントのパターンが増えるので、その都度精度を向上させたいお客様から任意のドキュメントをいただきトレーニングを施します。この際にポイントは取引先のお客様企業ごとにテストデータと学習データを準備し、テストデータに対しての精度をお客様に確認いただくことで、文字抽出の精度の満足度にばらつきが出ないようにしていきます。
2.2. モデルの学習と評価
アノテーションが終わったら、 Document AI Workbenchで学習を開始します。学習後、テスト用のドキュメントを使ってモデルの精度(F1スコアなど)を評価し、合格ラインに達したらデプロイの準備完了です。
3. Document AIへのリクエストとAPIの利用
学習済みのカスタムプロセッサをアプリケーションから利用するには、 Google CloudのAPIエンドポイントを使います。
3.1. APIリクエストの実行
Document AIは基本的にREST APIで提供されており、これに認証情報と処理対象のファイルを渡します。
(1)プロセッサのエンドポイントURLカスタムプロセッサをデプロイすると、以下のような形式の エンドポイントURLが発行されます。
例:https://[region]-documentai.googleapis.com/v1/projects/[project-id]/locations/[region]/processors/[processor-id]:process
このURLは、まさに私たちらが Goのクライアントからリクエストを送る先、つまりデプロイされたカスタムモデルの「住所」になります。
3.2. 出力データの利用
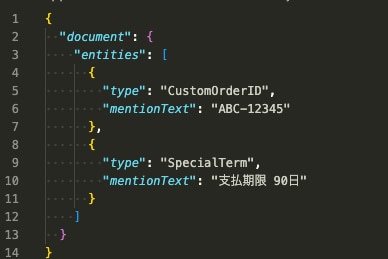
APIから返されるJSONレスポンスには、抽出されたデータが構造化されて含まれています。
まとめ:独自の壁を越えて
実際に私はお客様からのご要望に合わせて、指定の文字要素を抽出することで特定業務に対しての補助をすることができる機能を開発することができました。
これらの実践的な知見は、弊社が開発しているAI-OCR製品にも活かされています。お客様ごとのカスタマイズ要件に対応できる柔軟性や、精度向上のためのアノテーション手法、テストデータと学習データの適切な分離など、実案件で得た経験が製品開発の基盤となっています。そのため、弊社のAI-OCRは単なる汎用的なOCRツールではなく、お客様の具体的な業務要件に合わせて最適化されたソリューションを提供できるようになっています。




