AIコーディングはどう選ぶ?「自走するCursor」と「計画するAntigravity」のプロセス比較で学ぶ使い所
目次[非表示]
- 1.はじめに
- 2.前提:本記事の評価スコープについて
- 3.Google AntigravityのPlanning ModeとGemini 3 Pro (High) について
- 4.背景と目的
- 5.検証構成と技術スタック
- 5.1.【前提】
- 5.2.【検証タスクの要件】
- 5.3.【検証構成】
- 5.4.【検証環境:各ツールの特性を活かした構成】
- 6.「自走」と「堅実」を引き出すプロンプト戦略
- 7.具体例で見る「プロセスの違い」
- 8.成果物の比較
- 9.評価:開発プロセスにおける「質」の比較
- 10.UIの一例(共通の表示方針)
- 10.1.【Cursor Agent】
- 10.2.【Google Antigravity】
- 11.考察:使い分けの指針
- 12.結論:DIVX流・AIコーディングツールの使い分け基準
- 13.参考
- 14.お悩みご相談ください
はじめに
こんにちは、株式会社divx エンジニアの山本です。
現在、開発現場でも「Cursor Agent」や「Claude」といったツールを日常的に活用するようになってきました。そのスピード感と対話的な開発体験に助けられている一方で、新たな選択肢の可能性も検証したいと考えました。
そこで本記事では、Google AntigravityのPlanning Mode上で最新モデル Gemini 3 Pro (High) を稼働させた場合、同一タスクをCursor AgentとGoogle Antigravityの双方に実行させ、実装手順や振る舞い(ワークフロー)の違いを比較します。
前提:本記事の評価スコープについて
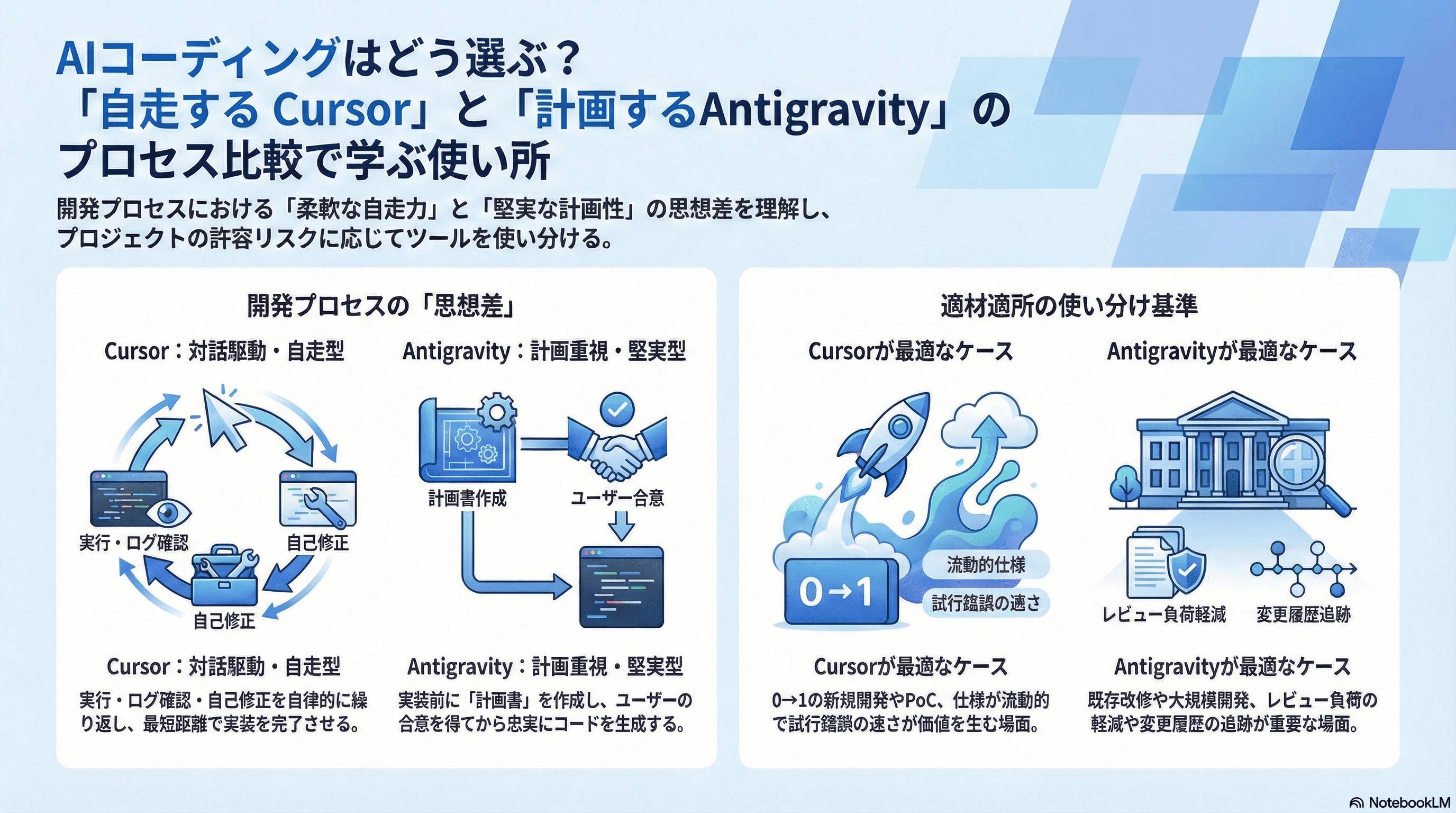
本検証の本質は、モデルの性能比較(Claude vs Gemini)ではなく、「Agent型(対話駆動)」と「Planning型(計画駆動)」という開発プロセスの比較にあります。
そのため、採用モデルの違いによるコード生成精度の差は今回の評価対象外とし、あくまで「ツールが提供するワークフローの違いが、開発体験にどう影響するか」に焦点を当てます。
Google AntigravityのPlanning ModeとGemini 3 Pro (High) について
Google AntigravityのPlanning Modeは、実装前にタスク分解と計画(Plan)を生成し、ユーザーの承認を経てから実装に進む「計画指向」のアプローチが最大の特徴です。この計画が一種のガードレールとして機能することで、仕様からの逸脱を抑制します。
これに対し、Gemini 3 Pro (High) は、膨大なコンテキストを保持した上でのコード生成と推論に強みを持っており、長い要件定義であっても漏れなく反映できる点が、このモードと非常に相性が良いと言えます。
背景と目的
開発者がAIエージェントに求めるのは、単なるコード生成能力だけではなく、柔軟な対応力や自律的な判断力です。
本記事の目的は、「対話型の柔軟な自走力(Cursor)」と「プロンプト重視の堅実な実装力(Antigravity)」が、同じ要件をどのような過程で満たすのかを具体例と共に示し、現場での使い分け判断に役立つ基準を整理することにあります。
検証構成と技術スタック
【前提】
検証用のベースコードとして、既存のシンプルなCLIツール(todo.py)を使用します。主要な関数を中心に抜粋し、その他は簡潔化しています。なお、このベースコードはCLI前提でUIを持たず、タスクの優先度(High/Low)も未実装です。
import sys import json import os TODO_FILE = 'todo_list.json' def load_todos(): if not os.path.exists(TODO_FILE): return [] with open(TODO_FILE, 'r') as f: return json.load(f) def save_todos(todos): with open(TODO_FILE, 'w') as f: json.dump(todos, f, indent=4) def add_todo(task): todos = load_todos() todos.append({'task': task, 'completed': False}) save_todos(todos) print(f"Added: {task}") def list_todos(): todos = load_todos() for i, todo in enumerate(todos): status = "[x]" if todo['completed'] else "[ ]" print(f"{i}: {status} {todo['task']}") if __name__ == "__main__": # 使い方: # python todo.py add "Buy milk" # python todo.py list command = sys.argv[1] if len(sys.argv) > 1 else None if command == "add" and len(sys.argv) > 2: add_todo(sys.argv[2]) elif command == "list": list_todos() else: print("Usage: python todo.py [add|list] [task]")
【検証タスクの要件】
UI化:CLI操作を廃止し、ブラウザ上で完結させる
機能追加:タスクに「優先度(High/Low)」を追加し、Highは赤色で強調表示する
データ維持:既存のJSONデータを壊さずに移行する
【検証構成】
アプローチA:Agent型プロセス(Cursor Agent / Agent Mode)
アプローチB:Planning型プロセス(Google Antigravity / Planning Mode)
【検証環境:各ツールの特性を活かした構成】
それぞれのツールが得意とするスタイルで検証を行いました。
※ 厳密な比較を行う場合は、通常は双方のエージェントで同じモデルを利用することが望ましいと考えています。ただし、本検証を行った時点のAntigravityでは、Claudeとして選択できるのが「Claude Opus 4.5 (Thinking)」のみであり、通常のClaude Opus 4.5とは動き方が異なる種類でした。そのため、本記事ではAntigravity側にはGemini 3 Pro (High) を採用しています。
なお、本記事の主な目的は、モデルそのものの性能差を評価することではなく、「Agent型(対話駆動)」と「Planning型(計画駆動)」の開発手順・振る舞いの違いを比較することにあります。
「自走」と「堅実」を引き出すプロンプト戦略
今回の挙動の違いは、ツールの特性に加え、以下の指示(プロンプト)設計によって意図的に再現させています。
Cursorへの「自走」指示
「Askモードで合意した文脈をAgentモードに引き継ぐ」手法をとりました。
「実装は任せるが、設計の前提だけは共有する」というスタンスにすることで、Cursorのエラー発生時の自己修正ループ(ログ確認→修正)を機能させています。
【Askモード】
@todo.py このCLIツールを、Streamlitを使ったWebアプリ(GUI)に作り変えたいです。 要件は以下の通りです。 1. タスクに「優先度(High/Low)」を追加する。 2. ブラウザ上でタスクの追加・削除・一覧確認ができるモックUIにする。 実装に入る前に、どのようなUI構成にするか、データの持ち方(JSON構造)をどう変えるか、設計案をMermaid図で描いて教えてください。
【Agentモード】
提示してくれた設計案に基づき、`app.py` としてStreamlitアプリを実装してください。 UIは直感的でモダンなデザインにしてください(例: 優先度Highは赤色で強調するなど)。
Antigravityへの「堅実」指示
単に要件を投げるのではなく、プロンプトで明確に「Step 1: 分析と計画」「Step 2: 実装」の段階的進行を強制しました。
これにより、「計画→承認→実装」というガードレールが機能し、仕様逸脱を防ぐ堅実な挙動を引き出しています。
あなたはGoogleの最高峰AIモデルとして、既存のPythonスクリプトのモダン化と機能拡張を行います。 現在ディレクトリにある `todo.py` を読み込んでください。 【依頼タスク: CLIツールのWebアプリ(Mock UI)化】 このCLIツールを、`Streamlit` を使用したWebアプリケーション(`app.py`)にリファクタリングしてください。 同時に、以下の新機能を追加してください。 1. 優先度管理: タスク追加時に `High` または `Low` を選択可能にする。 2. 視覚的UI: タスク一覧をテーブルまたはカード形式で表示し、優先度でソートやフィルタリングができるようにする。 【実行プロセス】 Planningモードの特性を活かし、必ず以下のステップで進行してください。 Step 1: 分析と設計 (Investigation & Planning) - 現在の `todo.py` のロジック(データの読み書き)をどう `Streamlit` の作法(Session Stateやウィジェット)に移植するか分析してください。 - 作成するアプリの画面構成(UI)と、データフローを Mermaid図 で可視化してください。 - 実装手順の計画を箇条書きで提示してください。 (私が計画を確認し「GO」を出したら、Step 2へ進んでください) Step 2: 実装 (Implementation) - `app.py` の完全なコードを作成してください。 - 既存の `todo.py` は残しつつ、新しい `app.py` だけで動作するようにしてください。
具体例で見る「プロセスの違い」
実際に「todo.py」をUI化するタスクを両ツールに依頼したところ、そのアプローチの違いが非常に顕著でした。
Cursor Agent:対話駆動・自走型
Cursorへ「UI化」を依頼した際、まず環境にStreamlitが未導入であることをCursor自身が即座に認識し、「pip install streamlit」を迷いなく提案されました。インストールが終わるや否や、すぐに動作可能な最小のUIを組み上げて見せました。
開発を進めていく中で、今度はUI上でKeyの重複やStateの不整合といったエラーに遭遇したものの、Cursorはこれらのログを手がかりに、自発的にレイアウトや状態管理の設計を修正し、何度も実装を繰り返しました。そのたびに、当初Mermaidで可視化していた設計や簡易ドキュメントも、Cursorが自律的にアップデートしていく様子がありました。
特に印象的だったのは、明確な追加指示を与えずともログや挙動から現在地を読み取り、臨機応変に“自己修正”する動きです。短いサイクルで実装を改善しつつ、「自走する開発パートナー」として高い完成度に到達してくれました。
Google Antigravity:プロンプトに基づいた「堅実な実装力」
一方のAntigravityは、やや対照的です。こちらから要件を伝えると、まずimplementation_plan.mdとして設計計画(UI構成やデータ移行方針など)が生成され、必ずユーザー側の合意(GOサイン)を待って次のステップへ進みます。
実装フェーズでは、計画の内容が忠実に反映されており、初版のapp.pyから優先度フィルタやテーブル/カード表示、Highの赤色強調など、細かな要件まですでに網羅されていました。もし追加変更が出ても、「計画差分」に応じた修正が行われるため、いつ・なぜ仕様が変わったのか、そのトレースもしやすい構成になっています。
Antigravityを導入してみて特に感じたのは、「実装に入る前の一呼吸」が明確に挟まることです。まずimplementation_plan.mdとして計画が提示され、こちらがGOサインを出すまではコード生成に進まないため、この段階で仕様の認識齟齬をかなり潰せました。その結果、実装開始後の手戻りは目に見えて減っています。さらに、途中で仕様変更が入った場合も、まず計画側を更新し、その差分に沿ってコードを修正するという流れが徹底されており、「どの指示がどの変更につながったのか」が追いやすく、成果物と指示の対応関係(トレーサビリティ)が自然と明瞭になりました。
成果物の比較
両者とも、要件(UI化・優先度追加・既存JSONの互換維持)を満たすモックUIを生成できました。見た目や機能レベルでは大きな優劣はなく、違いが出たのは「そこに到達するまでの歩き方」です。
評価:開発プロセスにおける「質」の比較
単純な所要時間の差(Cursorの方が早いが、これは承認プロセスの有無によるもの)以上に、以下の品質指標において明確なトレードオフが確認できました。
UIの一例(共通の表示方針)
Highのタスクは赤で目立たせる
フィルタ/ソートで高優先度を先頭に表示
priority未設定の旧データはLowとして扱う
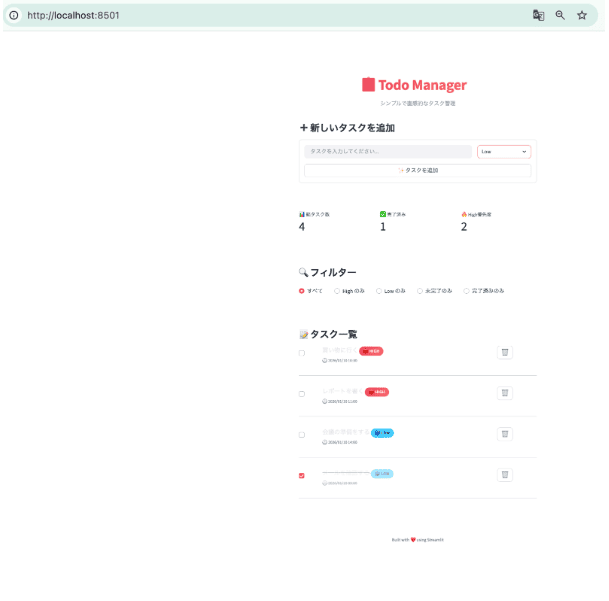
【Cursor Agent】
Cursor Agentで生成したStreamlit版TODO UI(同一要件)。High優先度は赤で強調され、フィルタ機能を備える。
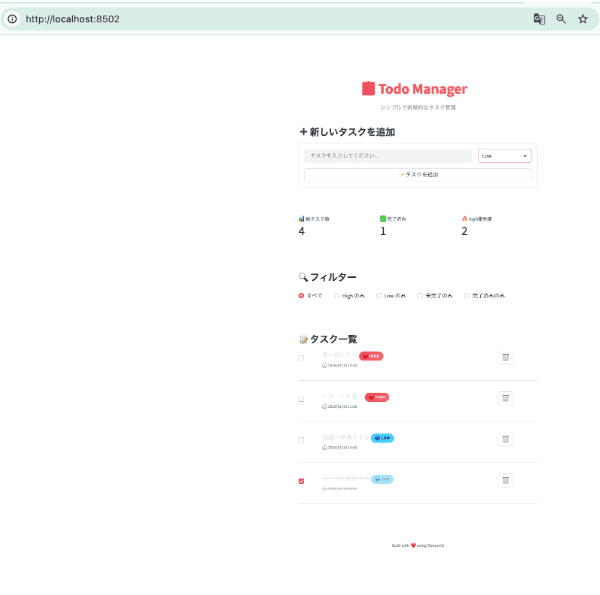
【Google Antigravity】
Google Antigravity(Planning Mode / Gemini 3 Pro)で生成したStreamlit版TODO UI(同一要件)。画面仕様はCursor版と揃っており、差はUIではなく実装プロセス(計画→承認→実装)に現れた。
考察:使い分けの指針
今回の検証を踏まえると、新規開発やプロトタイピング、あるいはアジャイル開発のように仕様が動きやすく、実装中の探索や試行錯誤が多い場面では、対話を重ねながら柔軟に軌道修正できるCursor Agentが真価を発揮します。
一方で、あらかじめ仕様が固まっている機能追加や、コーディング規約・アーキテクチャの遵守が求められる開発、大きめの要件を漏れなく反映したいケースでは、事前に計画を明文化し、その設計図に沿って着実に進められるGoogle Antigravityのアプローチが適していると感じました。
結論:DIVX流・AIコーディングツールの使い分け基準
DIVXとしての結論は、「どちらが優れているか」ではなく、プロジェクトの状況に応じてAIコーディングツールを戦略的に使い分ける、という点にあります。今回の検証結果を踏まえると、新規開発(0→1)やPoC、プロトタイピングのように、作りながら要件が動いたり、試行錯誤の速度が価値に直結する局面では、Cursor Agentを優先して選ぶのが合理的です。仕様が未確定な段階でも対話を起点に実装へ進められ、エラーやUIの微調整も短いサイクルで自己修正しながら「まず動くもの」に到達しやすいため、探索フェーズのコストを下げられます。加えて、1人開発や少人数での短期検証のように、合意形成よりもスピードが求められる体制とも相性が良いと感じました。
一方で、既存システムの改修や機能追加、リファクタリングのように、要件がある程度固まっていて、レビューや変更履歴の追跡が重要になる局面では、Google Antigravity(Planning Mode)を優先するのが適しています。計画を明文化し、承認を挟んでから実装に進むため、仕様漏れや認識齟齬をコード生成前に潰しやすく、結果として手戻りを抑えられます。また、変更が入った際も「計画差分→実装差分」という形で対応関係を残しやすいので、複数人開発やコードレビュー必須のプロジェクトにおいて、変更理由のトレーサビリティを担保しやすい点がメリットです。
つまりエンジニアに求められるのは、ツールの好みで選ぶことではなく、プロジェクトが許容できるリスク(スピード優先で多少のブレを許すのか、堅実さ優先で手戻りを極小化したいのか)と、チームの合意形成コスト(誰がどこまでレビューし、何を根拠に変更を承認する必要があるのか)を天秤にかけたうえで、CursorとAntigravityを適材適所で使い分ける判断力だと考えています。