

WebGPU×Gemma-3で構築するブラウザ完結型AI在庫管理 —— localStorageのデータをLLMが解釈する設計と実装
はじめに
こんにちは、DIVXの長谷川です。
「サーバーなし。クラウドなし。ブラウザだけでAI在庫管理はどこまで動くのか?」
2026年、WebGPUの進化により、私たちはLLMをブラウザ内に「閉じ込める」という新しい選択肢を手にしました。正直に言えば、ブラウザで動く小型モデル単体では、まだ「賢さ」に限界があるのも事実です。
そこで今回、AIには「意図の解釈」を、JavaScriptには「正確な計算」を分担させるハイブリッド設計を構築しました。単なるデータの保存先だったlocalStorageにAIの層を重ね、自然言語での操作を実現したプロトタイプの舞台裏と、実務で使える「設計の勘所」を共有します。
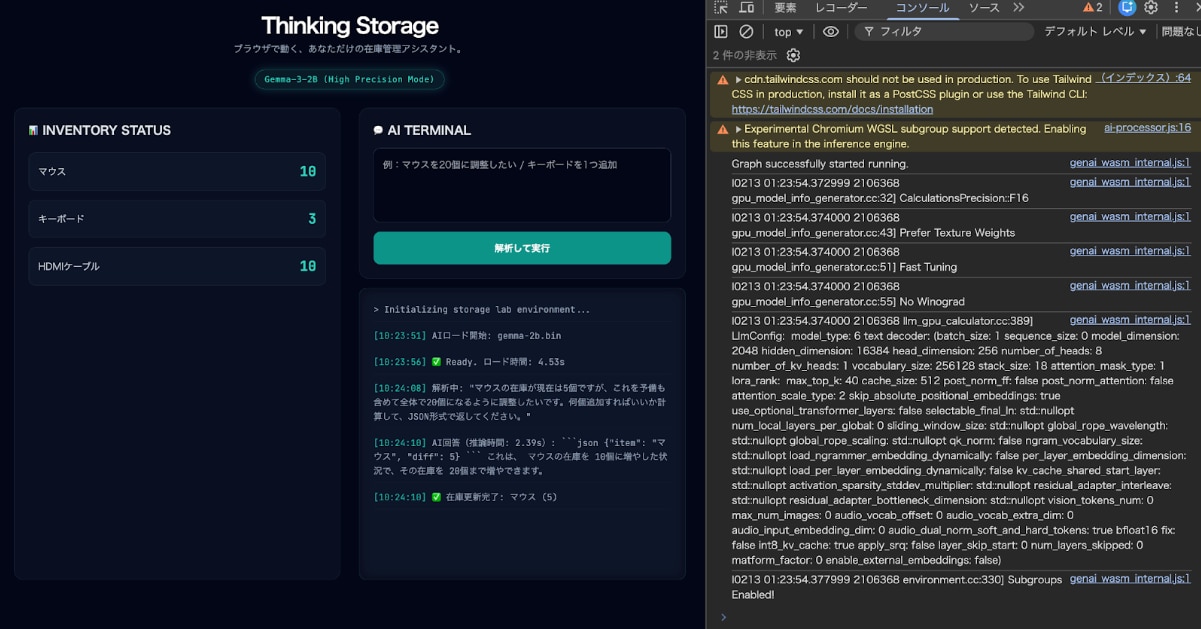
具体的には、このようにブラウザ上のチャット欄に指示を出すだけで、その場の在庫データが書き換わる操作体験が実現します。
AIへの指示: 「現在は5個ですが、全体で20個になるように調整したいです」
AIの解釈: json {"item": "マウス", "diff": 5} を自動生成
結果: ✅ 在庫更新完了: マウス (5)
上記のデモでは、AIが「マウスの在庫を調整したい」というユーザーの意図を完璧に読み取り、システムが処理可能なJSONデータを生成しています。
一方で、お気づきかもしれませんが、AIの回答にある diff: 5 という数値は計算ミスです(本来は 20 - 5 = 15 なので、15個追加が正解です)。2Bクラスの小型モデルにとって、「複雑な言葉の解釈」と「正確な算術」を同時にこなすのは、まだハードルが高いのが2026年現在のリアルな技術水準です。
しかし、心配はいりません。 本プロジェクトでは、AIに計算を任せず、「意図の解釈(AI)」と「正確な計算(JavaScript)」を分担させるハイブリッド設計を採用しました。この「役割分担」こそが、不安定な小型モデルを実務レベルのシステムへと昇華させる鍵となります。その具体的な実装パターンを詳しく解説していきます。
この記事はこんな方にオススメです
- WebGPUや小型LLMを実務レベルでどう制御するか知りたいエンジニア
- 機密データを扱うため、オフライン・エッジでのAI活用を模索している設計者
- 自然言語による直感的なデータ操作をアプリに実装したいUXデザイナー
この記事でわかること
本記事では、実際に手を動かして見えてきた、エッジAI運用の「勘所」を3つのポイントで解説します。
- なぜ1Bではなく2Bモデルか? 起動速度と精度のトレードオフを実測検証
- 起動の速い1Bモデルで見られた「無限ループ」などの不安定な挙動と、2Bモデル(実測4.37s〜5.01sでReady)を選択した判断基準を公開します。
- AIの算術ミスを防ぐ、JavaScriptとAIのハイブリッド設計
- AIには「意図の解釈」を、プログラム(JS)には「正確な計算」を。それぞれの得意分野を分担させることで、計算ミスのない在庫更新を実現する設計を提案します。
- 2Bモデルの「揺らぎ」を吸収し、システムを安定させる防御的パース
- AIが出力する不安定なJSONデータを安全に処理し、システム全体を止めないための「ガードレール」としての実装テクニックを紹介します。
検証環境
本記事の計測値は、以下の環境で取得しています。
- ブラウザ: Google Chrome 131(WebGPU有効)
- GPU: NVIDIA GeForce RTX 3060(VRAM 12GB / F16演算対応を確認済み)
- ランタイム: MediaPipe LLM Inference API(Google AI Edge SDK)
- モデル: Gemma-3-1B-it / Gemma-3-2B-it(MediaPipe用 .bin 形式)
- 計測データ:
- ロード時間: 約4.4秒〜13.5秒
- 推論速度(2B): 約1.13秒〜4.8秒
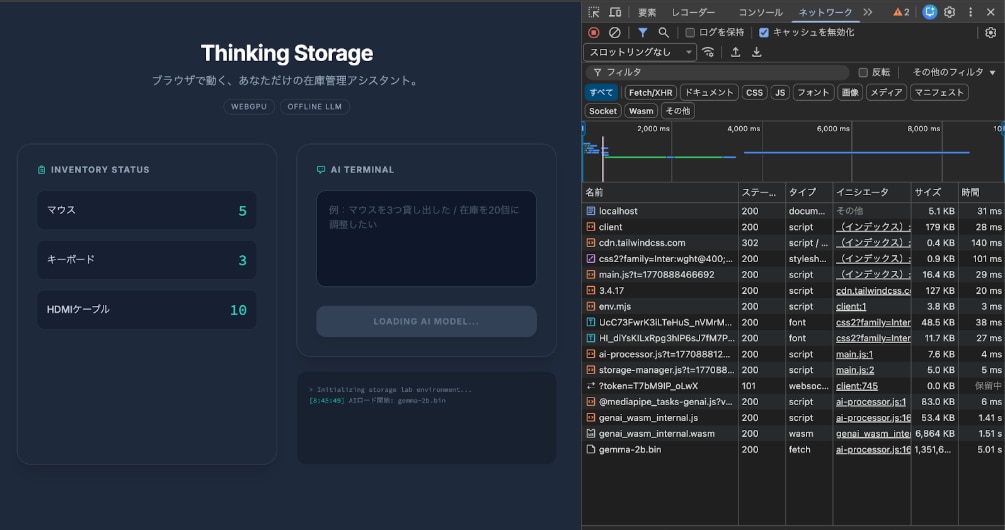
ネットワークタブを見ると、1.3GBのモデルファイルがブラウザに直接読み込まれている様子がわかります。約5秒で完了と、意外にスムーズです。
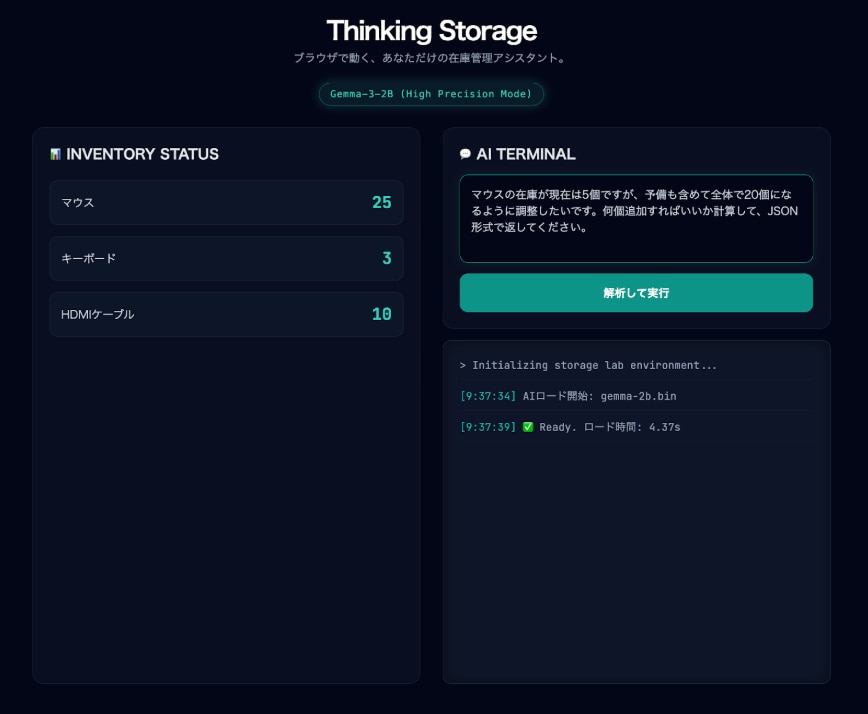
無事に2Bモデルが立ち上がりました!起動時間はわずか4.37秒。これくらいの速さなら、待ち時間もほとんど気になりません。
モデル選定:ロード時間と推論精度のトレードオフ
エッジAIでは、クラウドAPIとは異なり「モデルのロード待ち」が体験に直結します。「起動の速さ」か「推論の質」かの比較検証結果が以下です。
モデル | ロード時間 | 推論速度 | 推論の安定性 | 評価 |
|---|---|---|---|---|
Gemma-3-1B | 約4.4秒〜 | 約1.0秒(注1) | 不安定。回答がループ(無限タグ出力)しやすい | 速度は魅力だが、実用には課題あり |
Gemma-3-2B | 約5.0秒〜13.5秒 | 約1.13秒〜4.8秒 | 良好。指示への忠実度が高い。 | 採用。信頼性を最優先 |
(注1) 出力のループが発生しやすいため、速度のみの参考値
検証の結果、起動速度の1Bか、精度の2Bかというトレードオフが鮮明になりました。
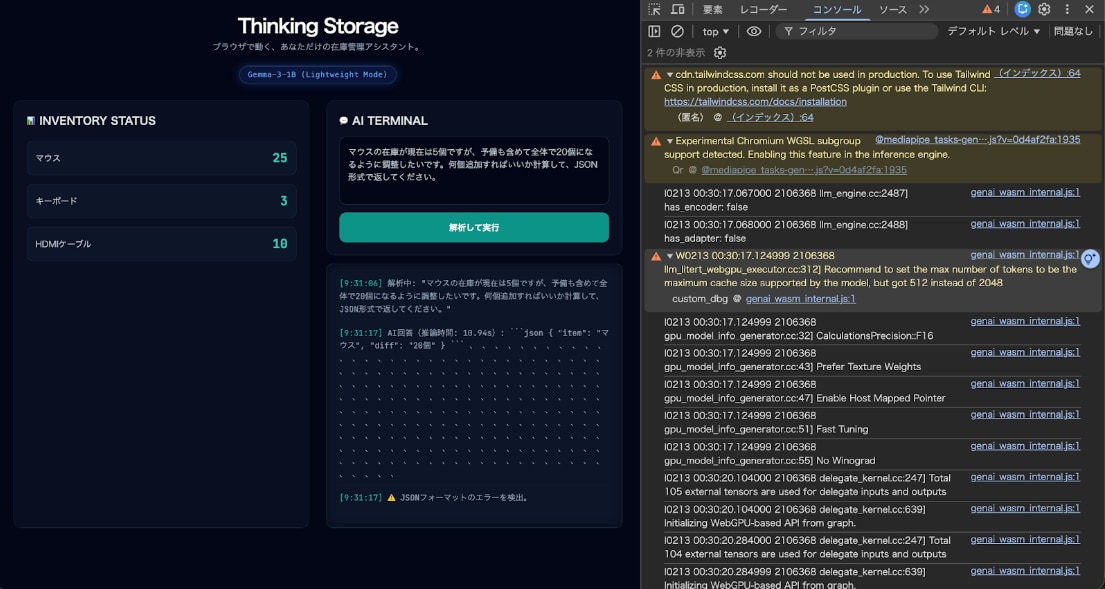
1Bモデルで発生した回答の無限ループです。最後はフォーマットエラーになってしまい、精度の課題が浮き彫りになりました。
なぜ数秒の差を飲んで「2B」を選んだのか
1Bモデルのロード時間は非常に魅力的ですが、論理推論において課題が見受けられました。具体的には、JSONを出力した後に ```json タグを数百回繰り返し出力する「無限ループ」に陥る現象が確認されています。
一方で、2Bモデルはロードに数秒余計にかかるものの、「ユーザーの意図を汲み取って正確なJSONを吐き出す」精度が高く、エラー率が大幅に低下しました。一度起動すればモデルはブラウザのメモリに常駐するため、初回ロードのコスト以上に、その後の推論の確実性がユーザー体験を支えると判断し、2Bモデルの採用に至りました。
実装のポイント:「AIの解釈」と「ロジック」を分離する
小型モデルの運用では、AIに完璧を求めず、その「揺らぎ」をコードで補完する設計が鍵となります。
1. AIを「構造化データの翻訳者」にするプロンプト設計
ユーザーの曖昧な指示を、システムが処理可能なJSON形式へ変換させるため、以下のシステムプロンプトを構築しました。
あなたは在庫管理システムの抽出アシスタントです。 以下のルールを厳守し、ユーザーの入力からJSONのみを出力してください。
【ルール】
1. 出力形式: {"item": "商品名", "target": 数値}
2. 解説や挨拶は一切禁止。JSONのみを出力すること。
3. 商品名は「マウス」「キーボード」「HDMIケーブル」から選択。
指示: 「${inputText}」
JSON:このプロンプトでは、文末を JSON: という形式で止める手法を採用しています (注2) 。これにより、小型モデルでも出力フォーマットが安定しやすくなります。
(注2) AIに「答えの書き出し」をあらかじめ指示しておくことで、出力フォーマットの崩れを防ぎ、生成の安定性を高める狙いがあります。
2. 算術処理をAIの責務から分離する
初期テストでは、AIが在庫の引き算を間違える「算術ミス」が頻発しました。そのため、AIには「最終的な目標数(target)」の抽出だけを任せ、現在値との差分計算はJavaScript側で行う設計を採用しました。
// AI回答から目標数(target)のみを取得(計算はAIに任せない)
const targetCount = parseInt(result.target);
const currentStock = storage.getAll()[itemKey];
if (itemKey && currentStock !== undefined && !isNaN(targetCount)) {
// 差分計算はJavaScriptが担当
const diff = targetCount - currentStock;
storage.update(itemKey, diff);
updateUI();
}
2Bモデルによるデータ抽出の成功例です。指示を正しく解釈し、即座に在庫更新まで完了できています。
3. 出力テキストの正規化とJSONデータの抽出
2Bモデルであっても、回答の末尾に解説文を付け加えてしまい、標準的な JSON.parse() が失敗するケースがあります。これを防ぐため、AIの回答から純粋なJSON部分のみを特定して取り出す「クレンジング処理」を実装しました。
/**
* AIの回答からJSON部分を特定し、構造化データとして抽出する処理
*/// 1. 回答の末尾にある余計な解説を、最初の閉じカッコ '}' の位置で切り出す
const closeIndex = response.indexOf('}');
let jsonCandidate = (closeIndex !== -1) ? response.substring(0, closeIndex + 1) : response;
// 2. 開始カッコ '{' を探し、データの開始地点を特定する
const openIndex = jsonCandidate.indexOf('{');
if (openIndex !== -1) {
jsonCandidate = jsonCandidate.substring(openIndex);
} else {
// 3. 開始カッコが欠落している場合、先頭に補完してパースを試みる
jsonCandidate = '{' + jsonCandidate;
}
try {
const result = JSON.parse(jsonCandidate);
// 抽出したデータを用いて在庫更新処理へ
} catch (e) {
console.error("JSONパースエラー:", jsonCandidate);
}この「防御的なパース処理」により、AIの出力に多少のノイズが含まれていても、システムが停止することなく安定してデータを処理できるようになります。
まとめ:ブラウザLLM活用の指針
今回の検証を通じて、ブラウザ完結型エッジAIを実務に投入するための具体的な設計指針が得られました。
- 2Bモデルが現時点での最適解: 数秒のロード時間を許容できるユースケースであれば、1Bモデルの「暴走リスク」を避け、指示への忠実度が高い2Bモデルを選択するのが現実的です。
- AIとプログラムの役割分担: AIに計算や厳格なフォーマットを期待しすぎず、「解釈」はAIに、「実行(計算・保存)」はJavaScriptに任せるハイブリッド設計が、システムの信頼性を担保します。
- 防御的なパース処理の重要性: 小型モデルの出力には常に「揺らぎ」が生じることを前提とし、必要なデータのみを特定して抽出・整形するロジックを設けることが、安定稼働の鍵となります。
WebGPU×Gemma-3の組み合わせは、データを外部に送信しない「プライバシー保護」と、ネットワーク環境に左右されない「低遅延な推論体験」という、クラウドAIにはない独自の価値を提供します。今後は、IndexedDBを活用した大規模データのハンドリングや、基盤システムとの同期といった課題を解決し、より実用的なエッジAIプラットフォームの構築を目指します。
プロトタイプの先へ:実運用に向けた課題
今回構築したプロトタイプは、ブラウザ完結型エッジAIの可能性を示しました。しかし、ビジネスの現場で本格運用するには、さらなる壁があります。
大規模データのハンドリング:localStorageの容量制限(一般的に5〜10MB)の中で、数万点の在庫情報をどう扱うか。IndexedDBへの移行や、データの分割ロード戦略が必要になります。
基幹システムとの同期:ブラウザ上のローカルデータと、サーバー側の在庫管理システムとの整合性をどう保つか。オフライン時の変更をどうマージするかという、分散システムの古典的な課題に直面します。
モデルの配布とアップデート:数百MBのモデルファイルを全端末に配布・更新する仕組みも、エンタープライズ運用では避けて通れません。
ブラウザの先にある「閉域LLM」という選択肢
今回のプロトタイプは、あくまでブラウザ上で動作する2Bクラスの小型モデルによる概念実証(PoC)です。「データを外に出さない」という思想は共通していますが、より本格的な閉域環境でのLLM活用——たとえば、gpt-oss 120Bクラスの大規模モデルをオンプレミスで稼働させ、エンタープライズ規模のデータを扱うような用途——には、専用のインフラ設計が必要になります。
DIVXでは、こうしたエッジAIの知見を活かしつつ、閉域・エアギャップ環境で大規模言語モデルを安全に運用する「DIVX Local LLM」を提供しています。量子化技術によりハイエンドPC/ワークステーションでも稼働可能で、PoCから本番運用までを一気通貫で支援するソリューションです。ブラウザ完結型のエッジAIでは手が届かない領域に課題をお持ちの方は、ぜひご相談ください。



