AWS FargateでAI推論サーバーをデプロイした実践を紹介します
はじめに
こんにちは、DIVX R&Dエンジニアのyasunaです。
先日、高性能なAI推論モデルをVPC内のプライベートな環境にデプロイするタスクを担当しました。これは、高い精度が求められるAI-OCRのような専門的なAIソリューションを、お客様の環境にセキュアかつスケーラブルに提供するために行いました。
弊社のAI-OCRは、文字認識に特化したAIモデルによって画像やPDFから文字を抽出し、その文字をLLMに渡して、必要な情報だけを選別・整理します。これによって、データの入力作業が不要になり作業の大幅な効率化を実現することができます。
この記事では、AWSのFargate上にAI推論サーバーをデプロイした際に直面した、サーバー容量(CPUとメモリ)不足の問題と、それをどのように解決し、運用を見据えたインフラを構築したのかという過程を共有したいと思います。
この記事を読んで分かること
- FargateでのAI推論サーバーのデプロイ過程で、どのような問題に直面する可能性があるか。
- AIモデルを扱う場合に、Fargateのタスク定義で考慮すべきリソース設定。
- CloudWatch Logsを活用した、デプロイ後のタスクの状態確認とトラブルシューティングの方法。
背景
今回デプロイしたのは、画像やドキュメントから必要な情報を抽出する、高度なAI推論モデルを搭載したサーバーです。これを既存のVPC内にECSのFargateで動かし、同じVPC内の他のサービスから内部的に利用できるようにすることが目的でした。
Fargateは、サーバー管理の手間なくコンテナを実行できる便利なサービスですが、裏側ではAWSがリソースを管理しているため、タスクに割り当てるリソース量(CPU/メモリ)を適切に定義する必要があります。
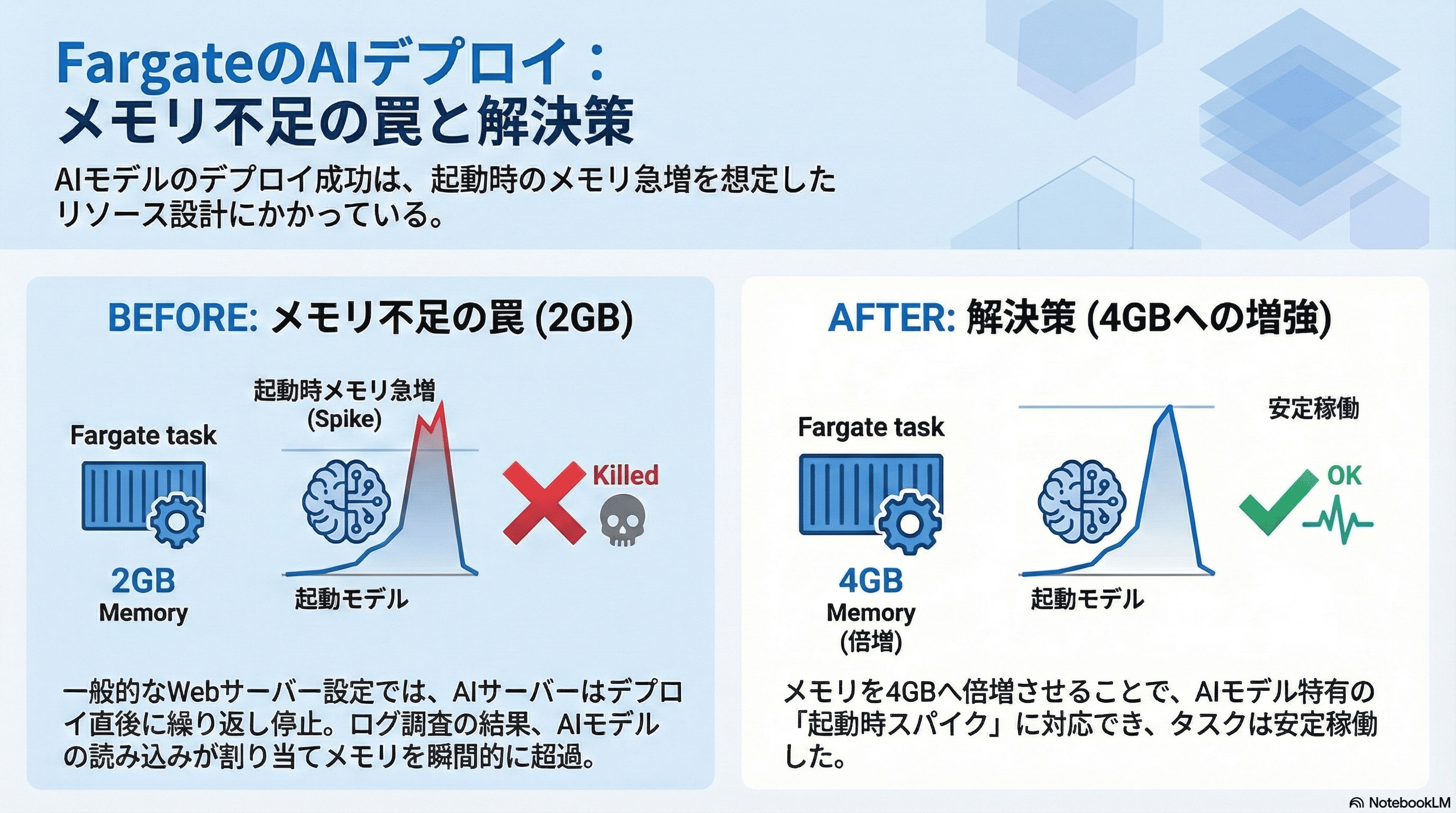
特に、今回扱うAIモデルは、その推論処理とモデル自体のロードに大量のメモリと一定のCPUパワーを必要とすることが事前に分かっていました。
試したこと
最初のデプロイでは、一般的なWebサーバーを想定した比較的控えめなリソース設定(例:CPU 1024 / Memory 2048MB)で試してみました。CloudFormationを使ってECSサービスとタスク定義を反映させ、デプロイが完了したように見えたものの、タスクが立ち上がってもすぐに終了してしまう状態が続きました。
1. ログの追跡
まずは何が起きているのかを知るため、デプロイされたタスクのログを追跡しました。
Bash
CloudWatch Logsから直近のログをtailする
aws logs tail /ai-ocr/stg/stg-ocr-mcp --since 5mログを確認すると、アプリケーション自体が起動エラーを起こしているのではなく、コンテナの起動直後に「Killed」(強制終了)されていることを示すメッセージが見つかりました。これは、Linuxのメモリ不足時に発生するOOM (Out Of Memory) Killerによってプロセスが終了させられた可能性が高いことを示唆していました。つまり、AIモデルをメモリにロードしようとした時点で、割り当てられたメモリ容量を超過してしまったのです。
2. タスク定義のリソース増強
この考察に基づき、タスク定義のCPUとMemoryの割り当てを段階的に引き上げる対応を行いました。具体的には、メモリを倍の4096MBに、CPUを2048(2vCPU相当)に設定し直しました。
この変更は、デプロイ手順書に基づき、params.jsonファイルを更新した後、CloudFormationのupdate-stackコマンドで適用しました。
JSON
// env/stg/params.json の一部を更新
// ...
{
"ParameterKey": "TaskCpu",
"ParameterValue": "2048"
},
{
"ParameterKey": "TaskMemory",
"ParameterValue": "4096"
},
// ...このリソース増強を反映して再デプロイしたところ、タスクが無事に安定して稼働し始めました。CloudWatch Logsを確認すると、「Killed」メッセージが出ることなく、AIサーバーの起動ログが流れ、最終的なヘルスチェックにも成功していることを確認できました。
考察
今回の経験で、AI推論サーバーにおけるリソースの見積もりの重要性を改めて実感しました。
一般的なWebアプリケーションであれば、アクセス負荷に応じてCPUやメモリを調整すれば済みますが、AIモデル、特に大規模なものは、起動時やモデルロードの瞬間に一気に大量のメモリを消費するという特徴があります。この初期スパイクに対応できるだけの余裕を持たせたリソースを、Fargateのタスク定義に設定しておく必要があったのです。
また、デプロイ後の問題解決においては、インフラ側のログを正確に読み解く力が不可欠です。今回の「Killed」というシンプルなログメッセージ一つから、原因がアプリケーションのエラーではなく、インフラのキャパシティ不足にあると切り分けられたことが、迅速な解決に繋がりました。
まとめ
この一連の作業を通して、AIモデルを扱う開発では、アプリケーションのコードだけでなく、モデルの特性に応じたインフラのリソース設計が大切になっていくと感じました。
今後も、AI活用とインフラ構築の両面で、実践的な学びを継続的に共有していきたいと思います。ぜひ参考にしていただけると嬉しいです。