Codex vs Claude:AIコードレビューの質を左右するのは「モデル」ではなく「文脈(コンテキスト)」だった話
はじめに
こんにちは、DIVX エンジニアの森川です。
本記事では、AIエージェントとして注目されるCodexとClaudeを実際のPull Request(PR)で比較検証し、そこから得られた「生成AI運用の重要なファクト」についてまとめます。
今回は以下の2つのツールを使用し、それぞれの特徴や使い勝手を検証しました。
- Codex
- Claude
この記事を読むことで、以下の知見が得られます。
- ツールごとの得意なレビュー観点の違い
- レビューの精度を落とす意外な原因(コンテキスト問題)
- 実務でAIレビューを効果的に運用するための具体的なアクション
背景と課題
私が生成AIによるセルフレビューの導入を検討した背景には、以下の2つの課題がありました。
- 新案件でのドメイン知識不足 最近、新しい案件にアサインされましたが、まだドメイン知識が十分ではありません。不慣れな環境でも実装品質を担保するため、セルフレビューが必要だと感じました。
- レビュアーの負担増加 AIアシスタントの普及により、生成AIが生成するコードの量は増え続けています。その一方で、チェックする人間のレビュアーにかかる負担は増大しています。事前に生成AIで形式的なミスや初歩的なバグを潰しておくことは、チーム全体の生産性向上に不可欠だと考えました。
導入構成と検証内容
今回の検証では、プロダクトの管理画面におけるリファクタリングのPull Request(PR)を対象にしました。
検証対象のPR概要
- 内容: 商品データ管理画面の改修(オートコンプリート化、即時検索、検索用セレクター追加など)
- 変更規模: 5コミット(+522 / -62)
使用したプロンプト CodexとClaudeに対し、全く同じ以下の依頼を投げました。
「feature/hoge(作業ブランチ名)のコミットした内容に問題がないかレビューしてください。またレビューする上でCLAUDE.mdの内容に沿っているかも合わせて確認してください。」
実装の工夫・検証結果
実際にレビューを行ってみると、ツールによって明確な違いが見えてきました。また、運用上の「落とし穴」にも気づくことができました。
1. ツールごとの指摘傾向の違い
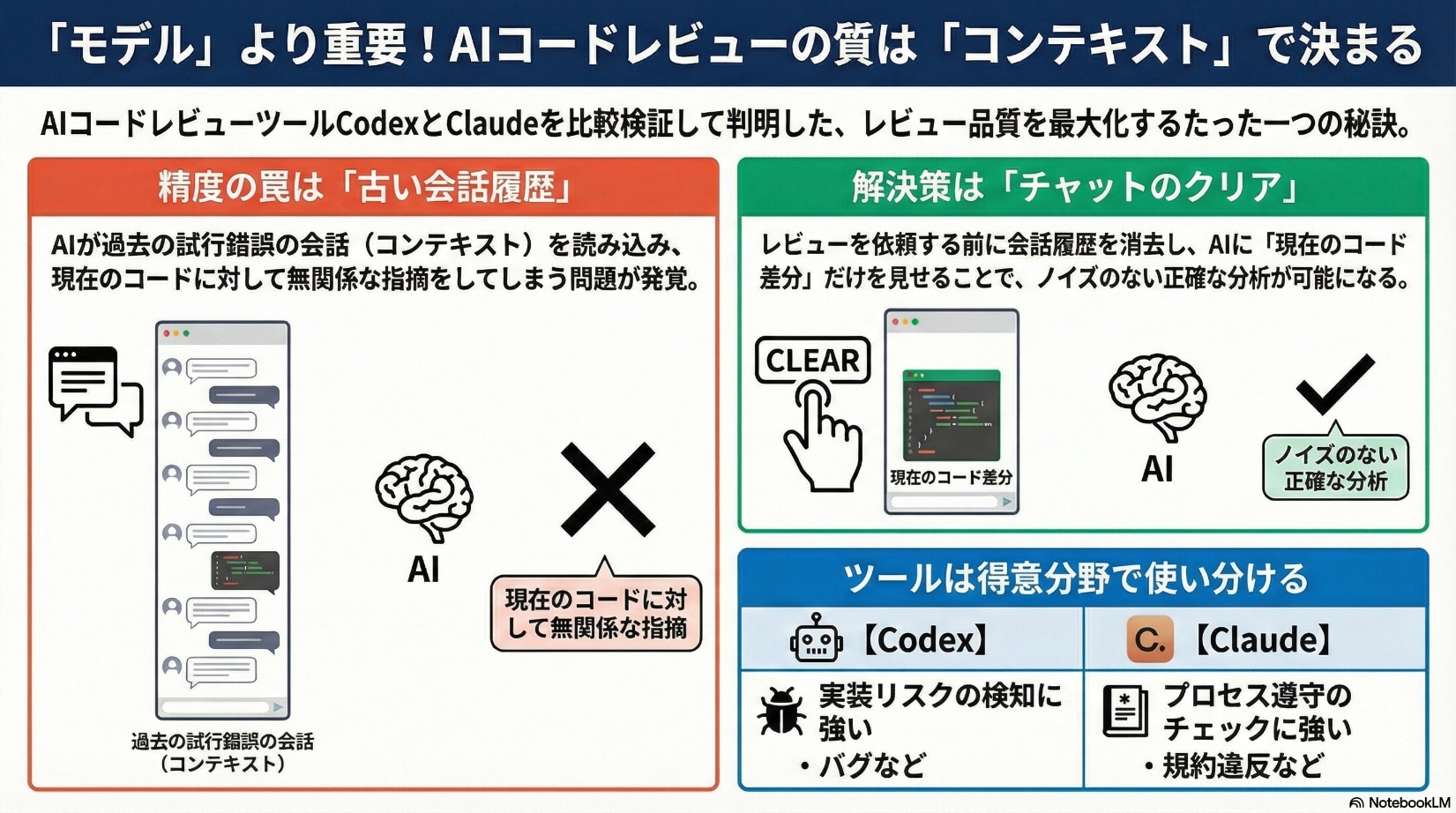
Codex:実装リスクの検知に強み Codexは、コードの挙動やパフォーマンスへの影響など、「実害」の可能性を指摘する傾向にありました。
- 鋭い指摘:
- カテゴリ選択時に onChange と onCategoryChange が重複して走り、再レンダリングが無駄に発生する可能性。
- 入力のたびにAPIリクエストが発生する仕様への負荷懸念。
- 特徴: ドキュメントの形式的なルールよりも、動いた時のリスクにフォーカスしています。
Claude:プロセス遵守と具体的な修正提案に強み Claudeは、プロジェクトルール(CLAUDE.md)への準拠状況など、「コンプライアンス」の観点で厳格でした。
- 主な指摘: コミットメッセージの形式違反(種別は大文字、署名必須など)。
- 具体的な提案: 単に指摘するだけでなく、「このコミットは REFACTOR にすべき」といった具体的な修正案を提示し、手戻りを減らす配慮が見られました。
2. コンテキスト問題の発見(実装の工夫)
検証中に興味深い事象が起きました。Claudeが「実装方針をAからBへ転換した」経緯に対し、すでに修正済みの古い方針(A)に基づく指摘をしてきたのです。
原因の分析: ログを確認すると、「作業中のチャット履歴(コンテキスト)が残っていたこと」が原因でした。 実装時の試行錯誤のログが残ったままレビューを依頼したため、Claudeが「現在のコード(差分)」と「過去の会話の経緯」を混同してしまったのです。
改善策: レビュー依頼時は「チャットのクリア」を徹底する。これにより、純粋なコードのみを生成AIに渡すことができ、バイアスのない客観的なレビューが可能になります。
効果
今回の比較検証を通じて、以下の効果と知見が得られました。
それぞれの得意領域を理解し使い分けることで、「実害リスク」と「修正提案・形式不備」の両方を効率的にカバーできることが分かりました。
チーム文化と運用体制
この検証を踏まえ、現在は以下の運用体制(アクションプラン)を個人的に実践しており、チームへの展開も視野に入れています。
- レビュー時の「チャットクリア」の徹底
- 実装コンテキストとレビューコンテキストを明確に分離します。
- ツールの役割分担
- Codexで「守:壊れていないか」を確認し、Claudeで「攻:拡張性を含めた提案」を確認するダブルチェック体制です。
今後の展望
「AIが間違ったことを言った」と切り捨てるのは簡単ですが、その原因を構造的に分析すると、人間側の「情報の渡し方(コンテキスト管理)」に改善の余地があることが分かります。
なお、検証の公平性という点では、ルール定義ファイル(mdファイル)の有無も結果に大きく影響しています。今回はチームで運用されている CLAUDE.md を使用したため、Claudeが形式チェックに強かったのは必然とも言えます。ツール導入の際は、使用するツールに合わせた定義ファイル(AGENTS.mdなど)を整備することが、レビュー品質を最大化する前提条件となるでしょう。
正しいアウトプットを得るには、正しいインプットが不可欠です。 今後はこの知見を活かし、「生成AIに余計な情報を与えず、シンプルに準拠させたい定義ファイルや事実だけを見せる」運用をチーム全体に広げていきたいと考えています。