

Google Cloud Document AI を使用してOCRの読み取り箇所を可視化する
はじめに
こんにちは。DIVXでエンジニアをしている余吾です。
OCRを使ったアプリケーションを開発していると、「読み取った箇所をユーザーに見せたい」という要件が出てくることがあります。読み取り結果だけでなく、どこから読み取ったかを可視化することで、ユーザーが結果を確認しやすくなり、誤認識があった場合にもすぐに気づくことができます。
Google Cloud Document AIはOCRの解析結果に位置情報(バウンディングボックス)を含めて返してくれます。この記事では、その位置情報を使って読み取り箇所を枠線で可視化するアプローチを紹介します。
なぜ読み取り箇所の可視化が必要か
OCRアプリケーションにおいて可視化には以下のようなメリットがあります。
ユーザーの信頼性向上: 「どこから読み取ったか」が見えることで、OCR結果への信頼感が増す
誤認識の早期発見: 枠線の位置がずれていれば読み取りミスにすぐ気づける
デバッグの効率化: 開発時に認識精度の問題を特定しやすい
UXの向上: ユーザーが結果を確認・修正する際の手がかりになる
特に請求書や帳票など複数のフィールドを読み取るケースではフィールドごとに色分けして表示することでどの値がどこから読み取られたかを直感的に把握できます。
Document AI の概要
Document AIはGoogle Cloudが提供するドキュメント処理プラットフォームです。機械学習を活用してドキュメントからテキストや構造化データを抽出できます。
プロセッサの種類
Document AIには用途に応じた様々なプロセッサがあります。
プロセッサ | 用途 |
|---|---|
OCR Processor | 汎用的なテキスト抽出 |
Form Parser | フォームのキー・バリュー抽出 |
Invoice Parser | 請求書の構造化データ抽出 |
Receipt Parser | レシートの構造化データ抽出 |
Contract Parser | 契約書の解析1990年11月 |
今回はInvoice Parserを例に、請求書から抽出したフィールド(数量・単価・金額など)を色分けして可視化します。
Invoice Parserが抽出するフィールド
Invoice Parserは請求書の構造を解析し、請求書の項目を自動で抽出します。以下はデフォルトで抽出される項目の一例です。
請求書番号(invoice_id)
請求日(invoice_date)
請求元/請求先(supplier_name / receiver_name)
明細行(line_item)
品目(description)
数量(quantity)
単価(unit_price)
金額(amount)
合計金額(total_amount)
処理の全体像
可視化処理の流れは以下のとおりです。
請求書画像をDocument AIに送信
抽出されたエンティティ(フィールド)を取得
各エンティティの位置情報(boundingPoly)を取得
正規化座標をピクセル座標に変換
フィールドタイプごとに色分けして枠線を描画
可視化された画像を出力
Document AIのレスポンス構造
可視化を実装するうえで重要なのがDocument AIが返すレスポンスの構造です。
エンティティと位置情報
Invoice Parserのレスポンスにはentities配列が含まれ、各エンティティには位置情報が付与されています。
{
"entities": [
{
"type": "total_amount",
"mentionText": "620,000",
"pageAnchor": {
"pageRefs": [{
"boundingPoly": {
"normalizedVertices": [
{ "x": 0.65, "y": 0.75 },
{ "x": 0.85, "y": 0.75 },
{ "x": 0.85, "y": 0.78 },
{ "x": 0.65, "y": 0.78 }
]
}
}]
}
}
]
}
理解すべきポイント
entities: 抽出されたフィールドの配列。
typeでフィールドの種類がわかるnormalizedVertices: 0〜1に正規化された4頂点の座標
properties:
line_itemのような親エンティティの中に子エンティティがネストされている
正規化座標とは
normalizedVerticesは画像サイズに対する比率(0〜1)で表現されています。実際のピクセル座標を得るには、画像の幅・高さを掛ける必要があります。
ピクセルX = normalizedX × 画像幅
ピクセルY = normalizedY × 画像高さ
また、座標値が0の場合はレスポンスから省略されるという仕様があるため、実装時にはデフォルト値の設定が必要です。
実装の概要
処理フロー
実装は大きく3つのステップに分かれます。
Document AIへのリクエスト
画像をBase64エンコードしてAPIに送信
抽出されたエンティティを含むレスポンスを取得
バウンディングボックスの抽出
entitiesとそのpropertiesをループ
normalizedVerticesをピクセル座標に変換
フィールドタイプに応じた色・ラベルを付与
- 画像への描画
SVGでポリゴン(枠線)を生成
元画像にオーバーレイ
凡例を追加して出力
実装上の注意点
実際の実装では以下のようなエッジケースへの対応が必要です。
座標値の欠損: normalizedVerticesで値が0の場合は省略されるためデフォルト値を設定
ネスト構造: line_itemの子要素(quantity, amount等)はpropertiesに含まれる
対象フィールドの絞り込み: 可視化対象のフィールドタイプをフィルタリング
これらの詳細な実装については別途技術資料をご用意しています。
実行結果
サンプルの請求書画像に対して実行した結果です。
入力画像
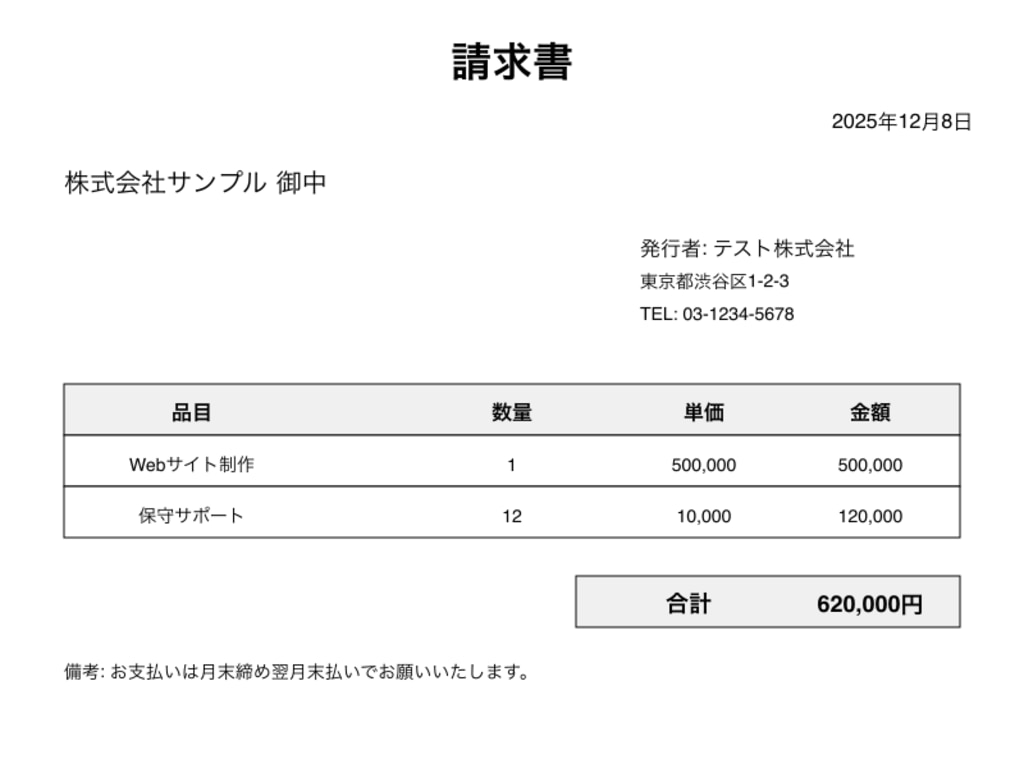
出力画像

各フィールドが以下の色で色分けされています。
フィールド | 色 | 抽出結果 |
|---|---|---|
品目 | 赤 | 抽出されず |
数量 | 青 | 抽出成功 |
単価 | 緑 | 抽出成功 |
金額 | 紫 | 抽出成功 |
合計金額 | オレンジ | 抽出成功 |
出力画像を見ると、数量・単価・金額などの数値フィールドは正しく抽出されましたが、日本語テキストの品目名は抽出されませんでした。品目名(「Webサイト制作」「保守サポート」)には枠線が表示されていないことがわかります。これはInvoice Parserが line_item/description フィールドを抽出できなかったためです。
課題と今後の展望
日本語対応の課題
今回の検証でInvoice Parserは日本語の品目名(line_item/description)を抽出できないことがわかりました。数値フィールドは問題なく認識されているため、日本語テキストのフィールドには課題があるのかもしれません。
アップトレーニングの可能性
Document AIにはアップトレーニング(Uptraining)機能があり、既存のプロセッサに対してカスタムデータを追加学習させることができます。
日本語請求書のサンプルを学習させることで認識精度を向上
独自のフィールドを追加定義することも可能
特定の帳票フォーマットに最適化できる
今後、日本語請求書でのアップトレーニングの効果を検証してみたいと思います。
詳細はDocument AI アップトレーニングのドキュメントを参照してください。
まとめ
Document AIの解析結果に含まれる位置情報(バウンディングボックス)を使って、OCRの読み取り箇所を可視化するアプローチを紹介しました。
ポイント
- Document AIは
normalizedVerticesで正規化された座標を返す 画像サイズを掛けてピクセル座標に変換する
フィールドタイプごとに色分けすることで読み取り箇所が一目でわかる
この可視化の仕組みはInvoice Parserに限らず、OCR ProcessorやForm Parserなど、Document AIの他のプロセッサでも同様に応用できます。
読み取り箇所を可視化することでユーザーは「どこから読み取られたか」を一目で確認でき、誤認識があった場合もすぐに気づくことができます。このような可視化機能を組み込むことでより信頼性が高く使いやすいOCRアプリケーションを開発できるのではないでしょうか。
本記事では概要とアーキテクチャを中心に解説しましたが、実際の実装にはバウンディングボックス抽出の詳細ロジックやSVGオーバーレイの具体的なコード、エッジケースへの対応など、さらに踏み込んだ技術的知見が必要です。
これらの実践的な知見は、弊社が開発しているAI-OCR製品にも活かされています。お客様ごとのカスタマイズ要件に対応できる柔軟性や、精度向上のためのチューニング手法など、実案件で得た経験が製品開発の基盤となっています。
詳細な実装についてのご質問やAI-OCR導入のご相談はお問い合わせフォームよりお気軽にご連絡ください。
参考リンク
- Document AI ドキュメント
- 処理レスポンスの構造
- Invoice Parser の概要
- アップトレーニングでプロセッサを改善する





